
1. Giới thiệu chung
Một quá trình (process) là một chương trình hoặc ứng dụng đang chạy trong hệ thống
Mỗi process đại diện cho một tác vụ riêng lẻ và có không gian bộ nhớ độc lập bao gồm không gian địa chỉ bộ nhớ riêng, bộ đăng ký CPU, stack, và các tài nguyên khác. Mỗi process đều được quản lý bởi kernel
Tạo và chấm dứt: Process có thể được tạo ra từ một quá trình cha thông qua hàm fork(). Quá trình có thể kết thúc bởi hệ thống thông qua hàm exit()
2. Process ID và Parent process ID
Mỗi process có một process ID (PID).PID là một số nguyên không âm đại diện cho một process cụ thể trong hệ thống Linux. Mỗi process có một PID duy nhất, và nó thường bắt đầu từ 1 và tăng lên khi tạo ra các process mới.
PID 1 thường đại diện cho process gốc (init) hoặc system, là process cha của tất cả các process khác trong hệ thống.
Để xem PID của process ta dùng hàm như sau:
#include <unistd.h>
pid_t getpid(void)
Linux kernel giới hạn process IDs nhỏ hơn hoặc bằng 32.767. Khi một process mới được tạo, nó sẽ được gán ID có sẵn tiếp theo. Mỗi khi đạt tới giới hạn 32.767, kernel sẽ đặt lại bộ đếm process ID của nó để các process ID được gán bắt đầu từ các giá trị nguyên thấp.
Chú ý: Khi nó đạt tới 32.767, bộ đếm process ID được đặt lại thành 300, thay vì 1. Vì nhiều process ID được đánh số thấp đang được sử dụng vĩnh viễn bởi các tiến trình nền của hệ thống và do đó sẽ lãng phí thời gian khi tìm kiếm process ID không được sử dụng trong phạm vi này.
Mỗi process đều có một process cha — process đã tạo ra nó. Một process có thể tìm ra ID của process cha bằng cách sử dụng lệnh gọi hệ thống getppid().
#include <unistd.h>
pid_t getppid(void);
Trên thực tế, process cha của mỗi tiến trình thể hiện mối quan hệ thông qua sơ đồ cây của tất cả các process trên hệ thống. Process cha của mỗi process đều có process cha riêng của nó.
Nếu khi process cha của bất kì process nào kết thúc, thì process con đó sẽ tiếp nhận process init ( process thủy tổ ) thành process cha của nó.
3. Memory layout của process
Bộ nhớ cấp phát cho mỗi một process được chia thành nhiều phần khác nhau. Thông thường chúng được gọi là các segments – Các phân đoạn vùng nhớ.
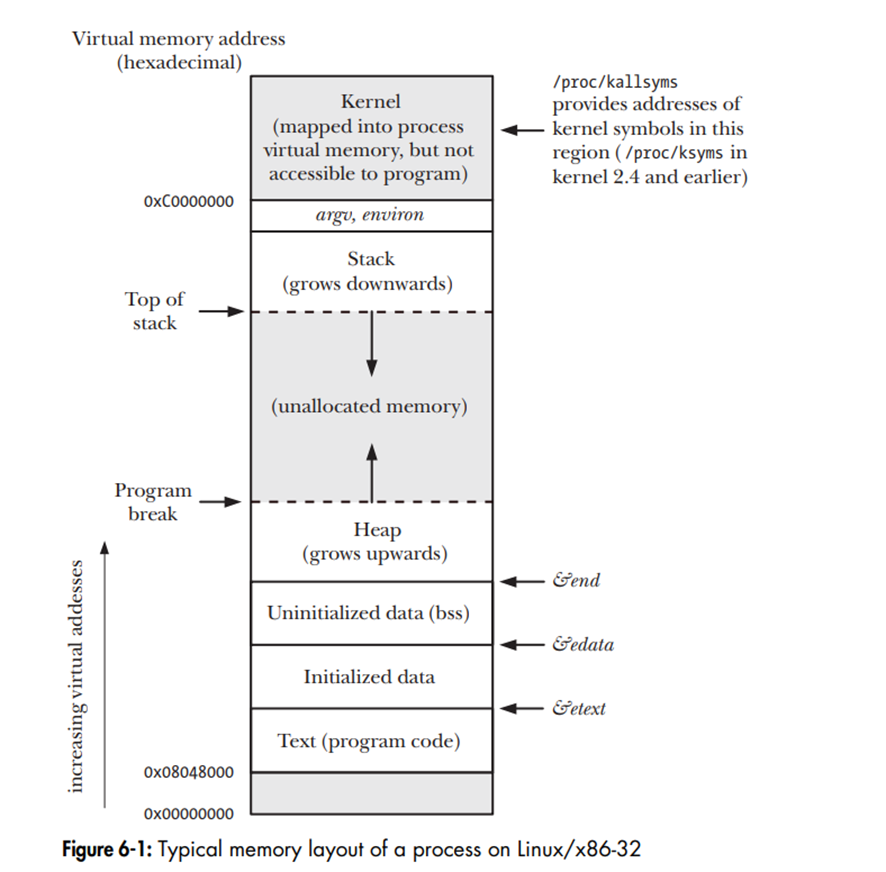
Text segment
Chứa các lệnh ngôn ngữ máy (machine-language) của program.
Bởi vì nhiều process có thể chạy từ một program. Do đó text segment được thiết lập là sharable để chia sẽ giữa các process nhằm tiết kiệm tài nguyên.
Segment này có quyền read-only (chỉ đọc)
Initialized data segment
Bao gồm các biến global (Toàn cục) và biến static (Tĩnh) đã được khởi tạo một cách tường minh.
Segment này có quyền read, write.
Uninitialized data segment
Bao gồm các biến global và biến static không được khởi tạo tường minh.
Trước khi bắt đầu chạy program, hệ thống sẽ khởi tạo giá trị cho các biến nằm trong segment này thành 0.
Segment này còn được gọi là bss segment.
Lý do cần phải phân chia các biến global và static vào hai phân đoạn bộ nhớ initialized và uninitialized là bởi, khi chương trình đang được lưu trữ trên ổ đĩa cứng, chúng ta không cần thiết cấp phát cho các biến uninitizlied bởi vì điều này sẽ làm kích thước của program tăng không cần thiết.
Segment này có quyền read, write.
Heap segment
Segment dành cho việc cấp phát bộ nhớ một cách tự động. Sử dụng các hàm như alloc(), malloc(), calloc()
Heap có thể co dãn tương tự stack. Điểm kết thúc của Heap được gọi là Program break.
Segment này có quyền read, write.
Stack segment
Có thể co dãn vùng nhớ bằng cách cấp phát hoặc giải phóng các stack frames.
Khi có lời gọi tới một hàm, một stack frame sẽ được tạo cho hàm đó nhằm mục đích lưu trữ các thông tin về các biến cục bộ, các arguments của hàm, giá trị return.
Stack frame sẽ được giải phóng sau khi hàm kết thúc.
Segment này có quyền read, write.
Ví dụ: Vị trí của các biến chương trình trong process memory segments
#include <stdio.h>
#include <stdlib.h>
char globBuf[65536]; /* Uninitialized data segment */
int primes[] = { 2, 3, 5, 7 }; /* Initialized data segment */
static int square(int x) /* Cấp phát Stack frame cho hàm square() */
{
int result; /* Stack frame của hàm square() */
result = x * x;
return result; /* Return value passed via register */
}
static void doCalc(int val) /* Cấp phát Stack frame cho hàm doCalc() */
{
printf("The square of %d is %d\n", val, square(val));
if (val < 1000) {
int t; /* Stack frame của hàm doCalc() */
t = val * val * val;
printf("The cube of %d is %d\n", val, t);
}
}
int main(int argc, char *argv[]) /* Cấp phát Stack frame cho hàm main() */
{
static int key = 9973; /* Initialized data segment */
static char mbuf[10240000]; /* Uninitialized data segment */
char *p; /* Stack frame của hàm main() */
p = malloc(1024); /* Trỏ tới bộ nhớ được cấp phát ở heap segment */
doCalc(key);
exit(EXIT_SUCCESS);
}
4. Virtual memory trong Linux
Trong hệ điều hành, mỗi process sẽ được cấp một không gian địa chỉ riêng biệt được đánh số từ 0 tới 4GB trên kiến trúc máy tính 32 bit ( từ 0 tới 64 GB trên kiến trúc máy tính 64 bit ). Tại không gian đó, địa chỉ sẽ được mapping vào trong dải địa chỉ vật lý chung của hệ thống.
Không gian bộ nhớ ảo của mỗi process được chia thành các đơn vị nhỏ có kích thước cố định được gọi là pages. Tương ứng với nó, trên RAM được chia thành các page frames có cùng kích thước
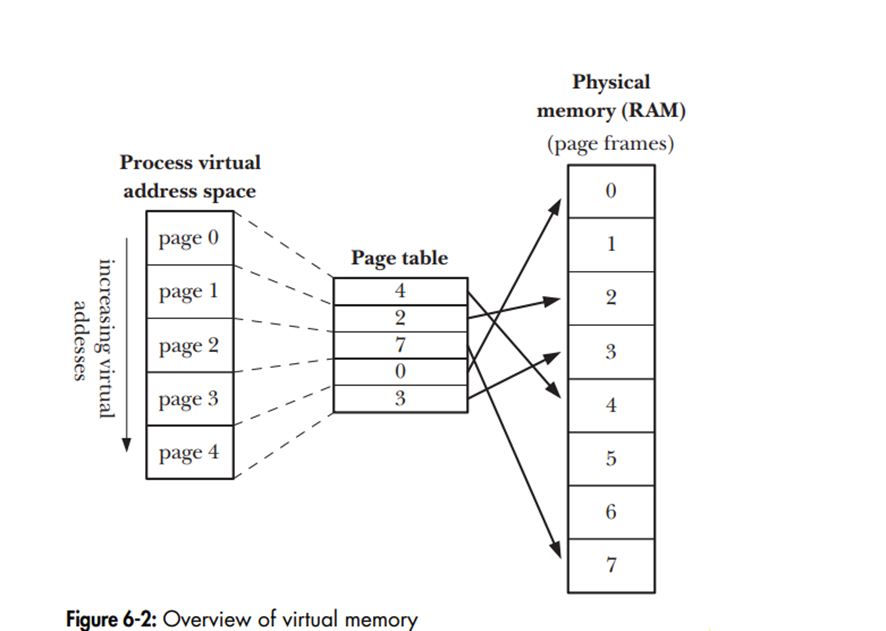
Kernel sẽ cung cấp một Page table cho mỗi process. Page table mô tả vị trí của mỗi page không không gian địa chỉ ảo của process.
Tuy nhiên, không phải tất cả các dải địa chỉ trong không gian địa chỉ ảo của process đều cần tới page-table entries. Thông thường, phần lớn không gian địa chỉ ảo không được sử dụng, do đó không cần duy trì page-table entries tương ứng trong page table.
Việc liên kết giữa địa chỉ ảo và địa chỉ vật lý trong RAM do phần cứng hỗ trợ bởi paged memory management unit( PMMU ). PMMU thực hiện việc mapping giữa virtual addresses và physical address
Cơ chế tách không gian địa chỉ ảo của một process khỏi không gian địa chỉ vật lý trên RAM mang lại nhiều lợi ích:
- Các process được cách ly với nhau và với kernel, do đó một process không thể đọc hoặc sửa đổi bộ nhớ của process khác hoặc kernel
- Khi cần thiết , hai hoặc nhiều process có thể chia sẻ bộ nhớ
- Các lập trình viên và các công cụ như trình biên dịch và trình liên kết không cần quan tâm đến cách bố trí vật lý của chương trình trong RAM
- Dung lượng bộ nhớ ( kích thước ảo ) của một process có thể vượt quá dung lượng của RAM
- Mỗi process sử dụng ít RAM hơn, nhiều process hơn có thể chạy đồng thời ở trong RAM
5. Command-Line Arguments (argc, argv)
Mỗi một chương trình đều bắt đầu khởi chạy từ hàm main(). Khi chạy chương trình các command-line arguments (tham số môi trường) sẽ được truyền qua 2 arguments của hàm main().
- argc: Chỉ ra số lượng tham số được truyền qua hàm main().
- argv: Là một mảng con trỏ trỏ tới các đối số command-line có kiểu char*.
Đối số đầu tiên trong số này( argv[0] ) là tên của chính chương trình đó. Danh sách con trỏ trong argv kết thúc bới NULL ( argv[argc] = NULL )
Ví dụ: Command-Line Arguments
#include <stdio.h>
int main(int argc, char *argv[])
{
int i = 0;
for ( i = 0; i < argc; i++)
{
printf("argv[%d] : %s \n", i, argv[argc]);
}
return 0;
}
Biên dịch chương trình trên ta được kết quả như sau:

6. Thao tác với Process
Trong số rất nhiều các ứng dụng hiện nay, việc tạo nhiều process (multiple process) để xử lý các tác vụ (task) giúp cho khả năng tính toán trở nên mạnh mẽ hơn.
Những sau đây được sử dụng để tạo lập, kết thúc, quản lý tiến trình cơ bản:
- fork(): Được sử dụng để tạo một tiến trình con mới. Tiến trình con là một bản sao của tiến trình cha.
- exec(): Sử dụng để thực thi một chương trình khác từ tiến trình đang chạy.
- exit(): Gửi trạng thái của kết thúc của tiến trình con tới tiến trình cha.
- wait(): Tiến trình cha có thể thu được trạng thái kết thúc của tiến trình con thông qua gọi wait().
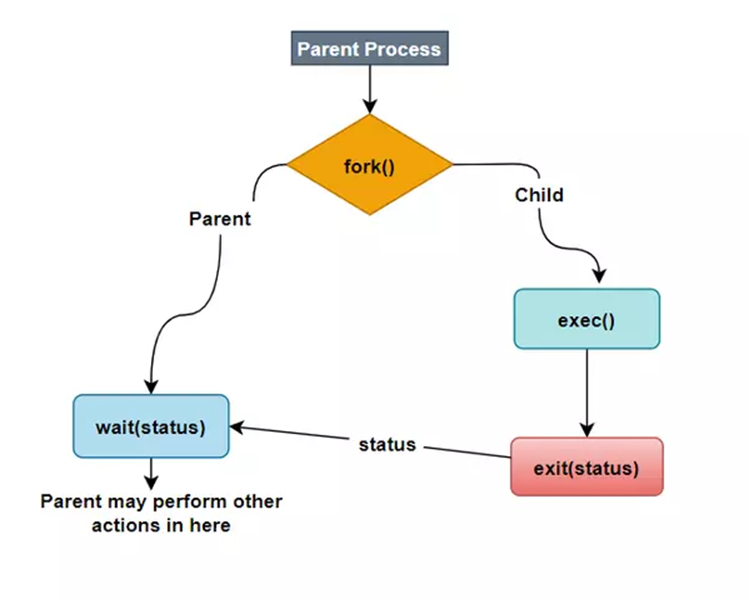
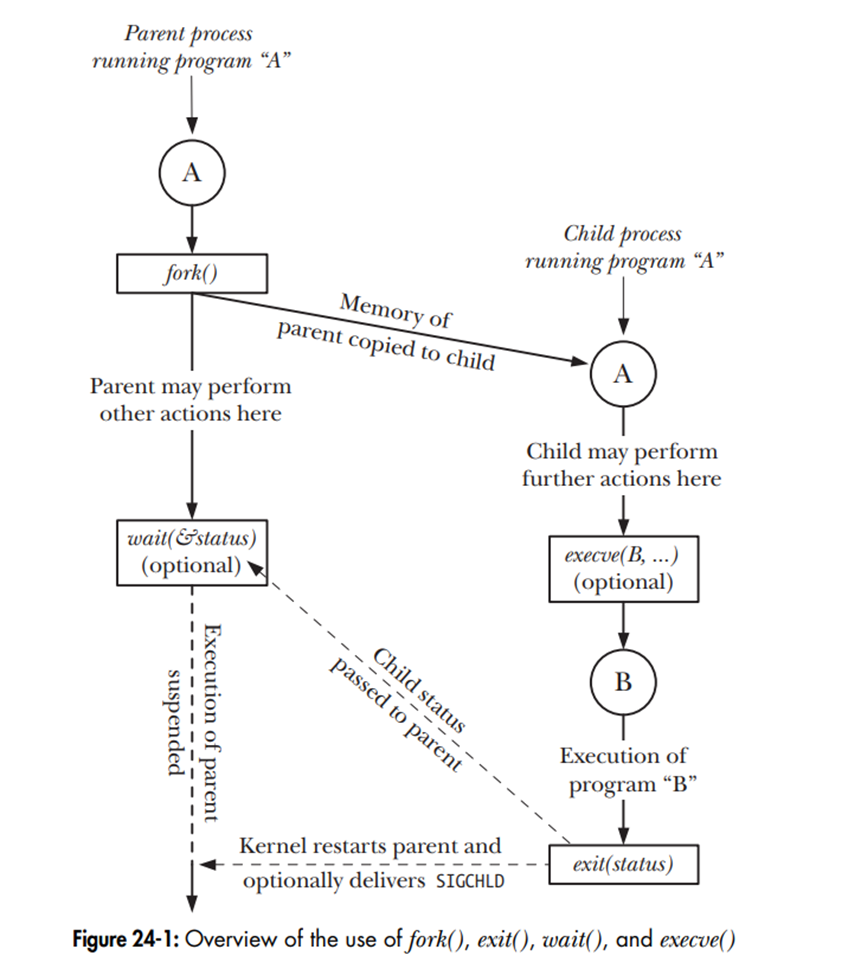
Fork() function
System call fork() cho phép tạo ra một process mới. Process thực hiện gọi fork() được gọi là tiến trình cha (parent process). Process mới được tạo ra gọi là tiến trình con (child process).
Sau khi lời gọi hàm fork() thành công, nó sẽ tạo ra một process con gần như giống với process cha ban đầu. Process con sẽ có các bản sao từ process cha: stack, data, heap, and text segments. Điều này có nghĩa là, khi bạn thay đổi dữ liệu trong process con sẽ không ảnh hưởng tới dữ liệu trong process cha.
#include <unistd.h>
pid_t fork(void);Nếu một process mới không được tạo ra, hàm fork() trả về -1.
Đối với process con, hàm fork() trả về giá trị 0, nó có thể thu được PID của mình thông qua việc gọi hàm getpid() và PID của process cha bằng getppid() .
Cùng xem thử pid của 2 process, 1 process và 1 process con
int main(int argc, char *argv[])
{
pid_t pidChild = fork();
/* pid_t tương đương int */
printf("hello pid : %d", getpid());
}pidChild nhận về pid của process con
Bạn sẽ thấy có 2 giá trí trả ra 1 pid 0 và 1 pid của process con. Trong tiến trình cha (parent process), giá trị trả về là PID (Process ID) của tiến trình con mới được tạo. Trong tiến trình con (child process), giá trị trả về là 0.
Vì thế chúng ta có thẻ nhận biết process child và parent bằng if else như thế này
int main(int argc, char *argv[])
{
pid_t pidChild = fork();
if(pidChild ==0){
printf("child pid: %d",getpid());
}
else{
printf("parent pid: %d",getpid());
}
}Chú ý: Process cha và con được lập lịch một cách độc lập với nhau. Không có sự phân biệt độ ưu tiên giữa cha và con. Do đó đôi khi process con có thể hoàn thành công việc của mình trước process cha.
Execl function
Hàm execl() trong hệ thống Unix và Linux là một hàm được sử dụng để thay đổi chương trình thực thi của một quá trình bằng cách thay thế mã máy tính của nó bằng mã máy tính từ một chương trình hoặc tệp cụ thể khác.
Hàm này sẽ thực thi một chương trình tại đường dẫn, kèm theo tham số truyền vào argv[]
#include <unistd.h>
int execl(const char *path, char *const argv[]);- path: Đường dẫn đến chương trình hoặc tệp thực thi mà bạn muốn chạy.
- argv[]: Danh sách các đối số được truyền đến chương trình thực thi.
Nếu hàm exec() thực hiện thành công, nó không bao giờ trả về. Thay vào đó, nó thay thế mã máy tính của quá trình hiện tại bằng mã máy tính của chương trình mới.
Sau khi gọi hàm execl(), OS sẽ load chương trình mới nằm tại pathname và thay thế vào không gian bộ nhớ của process hiện tại. Các câu lệnh còn lại của process hiện tại sẽ không được thực thi nữa.
Nếu hàm execl() gặp lỗi, nó trả về -1.
Ví dụ chúng ta có một chương trình C ( main.c ) sau sẽ in ra các giá trị truyền vào như ./main "hello world"nó sẽ in ra ".hello world"
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("argv[0]: %s\n", argv[0]); // In giá trị của argv[0]
if (argc > 1) {
printf("Command-line argument: %s\n", argv[1]); // In giá trị của đối số dòng lệnh (nếu có)
}
return 0;
}Thử với hàm execl() sẽ như sau:
int main() {
printf("This is the original program.\n");
// Thay đổi chương trình hiện tại thành main
execl("/home/asus/main","hello world");
// Nếu chương trình vẫn chạy đến đây, đó có nghĩa là execl thất bại
perror("execl");
return 1;
}Kết thúc process exit() và _exit()
Một process có thể hoàn thành việc thực thi của nó một cách bình thường bằng cách gọi system call _exit().
#include <unistd.h>
void _exit(int status);Đối số status truyền vào cho hàm _exit() định nghĩa trạng thái kết thúc (terminal status) của process, có giá trị từ 0 – 255. Trạng thái này sẽ được gửi tới process cha để thông báo rằng process con kết thúc thành công (success) hay thất bại (failure). Process cha sẽ sử dụng system call wait() để đọc trạng thái này.
Để cho thuận tiện, giá trị status bằng 0 nghĩa là process thực thi thành công, ngược lại khác 0 nghĩa là thất bại.
Trên thực tế, chúng ta sẽ không sử dụng trực tiếp system call _exit() mà thay vào đó sẽ sử dụng exit() của thư viện stdlib.h.
#include <stdlib.h>
void exit(int status);Ngoài ra, ta cũng có thể sử dụng return n trong hàm main() . Điều này tương đương với việc gọi exit(n) . Đây chính là lý do khi kết thúc hàm main() chúng ta thường hay sử dụng return 0 – success.
6. Zombie process
Là một tiến trình con đã kết thúc nhưng tiến trình cha không gọi hàm wait() hoặc waitpid() để thu thập thông tin về tiến trình con đã kết thúc. Do đó tiến trình con vẫn còn một bản ghi (entry) trong bảng tiến trình của hệ điều hành.
Vì vậy lúc này kernel sẽ giải quyết nó bằng biến tiến trình con thành tiến trình thây ma (zoombie process), điều này có nghĩa là hầu hết các tài nguyên do tiến trình con nắm giữ sẽ bị thu hồi và sử dụng cấp phát cho các tiến trình khác.
Tuy nhiên, nếu có quá nhiều zombie process, hệ thống có thể đạt đến giới hạn về số lượng tiến trình được tạo ra.
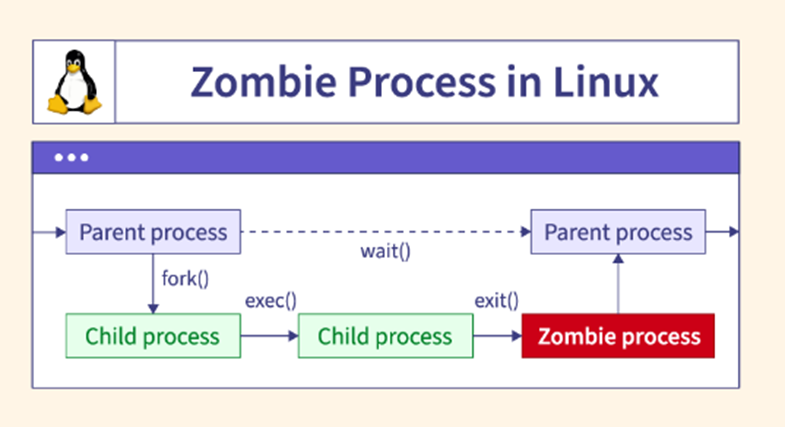
Ví dụ: Code sinh ra zombie process
#include <stdio.h>
#include <unistd.h>
int main()
{
int pid = 0;
pid = fork();
if( pid == 0)
{
execl("/home/loind/work/learn_Linux/unit4_process/main_argv", "xin chao", NULL); //run main_argv
}
printf("I'm parent\n");
sleep(1000);
return 0;
}
// Với nội dung của chương trình main_argv.c:
#include <stdio.h>
int main(int argc, char *argv[])
{
int i = 0;
char *a = NULL;
for(i = 0; i < argc; i++)
{
printf("argv[%d] = %s \n", i, argv[i]);
}
return 0;
}
Kết quả sau khi thực hiện chương trình:

Sử dụng command “ps -aux | grep main” thu được kết quả:

Ta process main_argv vẫn đang chạy với trạng thái Z+ ( zombie ) dù cho trong chương trình main_argv.c đã có return 0.
Có một bảng process ID (PID) cho mỗi hệ thống. Kích thước của bảng này là hữu hạn. Nếu quá nhiều tiến trình zombie được tạo, thì bảng này sẽ đầy. Tức là hệ thống sẽ không thể tạo ra bất kỳ tiến trình mới nào, khi đó hệ thống sẽ đi đến trạng thái ngưng hoạt động. Do đó, chúng ta cần ngăn chặn việc tạo ra các quy trình zombie.
Để ngăn chặn việc tạo ra các zombie process, thực hiện gọi hàm wait() ở process cha.
Wait() function
#include <sys/wait.h>
pid_t wait(int *wstatus)Wait sẽ block process cho đến khi 1 trong các process con kết thúc
Thông in trả về của process con được lưu vào con trỏ wstatus
Nếu trước khi gọi wait() process cha sử dụng fork để tạo ra nhiều process con thì hàm wait sẽ đợi process con nào kết thúc sớm nhất.
Ví dụ: Thực thi wait() ở ví dụ trên
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main()
{
int pid = 0;
int wstatus = 0;
pid = fork();
if( pid == 0)
{
execl("/home/loind/work/learn_Linux/unit4_process/main_argv", "xin chao", NULL); //run main_argv
}
else
{ // process cha
wait(&wstatus);
}
printf("I'm parent\n");
sleep(1000);
return 0;
}
Sau khi thực hiện chương trình trên, sử dụng command “ps -aux | grep main” thu được kết quả:

Như vậy, hàm wait() dã ngăn zombie process được tạo ra.