
Nhìn chung về AI và OpenAI
Trí tuệ nhân tạo (AI) là một lĩnh vực rộng lớn bao gồm nhiều công nghệ và phương pháp khác nhau nhằm tạo ra những cỗ máy có khả năng thực hiện các nhiệm vụ thường đòi hỏi trí thông minh của con người. Các thành phần của AI được mô tả trong sơ đồ sau:
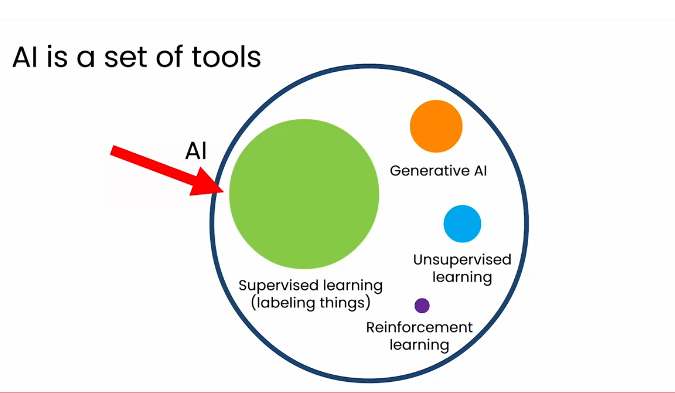
Các thành phần trong mô hình AI
Generative AI (GenAI): đề cập đến các hệ thống có thể tạo nội dung mới, chẳng hạn như văn bản, hình ảnh hoặc âm nhạc, dựa trên dữ liệu mà chúng đã được đào tạo. Những mô hình này, như GPT-4 của OpenAI, có thể tạo ra văn bản giống con người và được sử dụng trong các ứng dụng từ chatbot đến tạo nội dung.
Unsupervised Learning: liên quan đến việc đào tạo các mô hình AI trên dữ liệu mà không có phản hồi được dán nhãn. AI sẽ cố gắng tự mình tìm ra các mẫu và mối quan hệ trong dữ liệu. Kiểu học máy này rất phù hợp cho việc phân cụm các mục tương tự lại với nhau hoặc phát hiện điểm bất thường trong dữ liệu.
Reinforcement Learning: là một kiểu học máy trong đó tác nhân học cách đưa ra quyết định bằng cách thực hiện các hành động và nhận thưởng hoặc phạt. Phương pháp này thường được sử dụng trong chế tạo robot, chơi trò chơi và các ứng dụng khác trong đó việc đưa ra quyết định là rất quan trọng.
Supervised Learning: liên quan đến việc huấn luyện mô hình AI dựa trên các dữ liệu được dán nhãn, trong đó đầu ra chính xác được cung cấp. AI sẽ học cách để ánh xạ đầu vào thành đầu ra chính xác. Điều này được sử dụng cho các tác vụ như phân loại hình ảnh, nhận dạng giọng nói, và phân tích dự đoán.
OpenAI là tổ chức nghiên cứu hàng đầu trong lĩnh vực AI, được biết đến với việc phát triển các mô hình thế hệ tiên tiến như GPT-4. Những mô hình này là một ví dụ điển hình về GenAI, cho thấy tiềm năng của AI trong việc tạo ra văn bản mạch lạc và phù hợp với ngữ cảnh. OpenAI cũng góp phần thúc đẩy những tiến bộ trong các lĩnh vực khác của AI, bao gồm Reinforcement Learning và Unsupervised Learning, thông qua các sáng kiến và hợp tác nghiên cứu khác nhau.
Giới thiệu chung về GenAI
GenAI đã thay đổi cách chúng ta tương tác với máy móc, cho phép máy tính có thể tạo, dự đoán hoặc học hỏi mà không cần chỉ dẫn cụ thể từ con người. Với Chat GPT và OpenAI, chúng ta được chứng kiến những tiến bộ chưa từng có trong xử lý ngôn ngữ tự nhiên, các hình ảnh, tổng hợp video… GenAI là một subfield của AI và DL và nó tập trung vào sáng tạo nội dung như hình ảnh, văn bản, âm nhạc hoặc video… bằng cách sử dụng thuật toán và mô hình đã được huấn luyện trên những dữ liệu được cung cấp sử dụng công nghệ ML. Để hình dung rõ hơn về mối quan hệ giữa AI, ML, DL và GenAI, có thể coi AI là nền tảng, trong khi đó ML, DL, và GenAI đại diện cho các lĩnh vực nghiên cứu và ứng dụng ngày càng chuyên biệt và tập trung:
GenAI là một phân nhánh sâu hơn của DL, không sử dụng các mạng nơron sâu để phân cụm, phân loại hoặc suy đoán dựa trên dữ liệu hiện có mà nó sử dụng các mô hình mạng nơron đó để tạo ra nội dung hoàn toàn mới, từ hình ảnh đến ngôn ngữ tự nhiên, âm nhac, video…
AI đại diện cho lĩnh vực rộng lớn của việc tạo ra các hệ thống có thể thực hiện các nhiệm vụ, thể hiện trí thông minh và khả năng của con người và có thể tương tác với thế giới xung quanh
ML là một nhánh tập trung vào việc tạo ra các thuật toán và mô hình cho phép các hệ thống đó học hỏi và cải thiện chính nó theo thời gian và quá trình huấn luyện. Các mô hình ML học từ dữ liệu hiện có và tự động cập nhật tham số của chúng khi chúng phát triển lên.
DL là một phân nhánh của ML, nó bao gồm các mô hình ML sâu. Những mô hình sâu đó còn được gọi là mạng noron và đặc biệt phù hợp trong các lĩnh vực như thị giác máy tính hoặc xử lý ngôn ngữ tự nhiên. Khi nói về mô hình ML và DL, chúng ta thường đề cập đến các mô hình phân biệt, mục tiêu của chúng là đưa ra dự đoán hoặc suy luận các mẫu dựa trên dữ liệu
Mối quan hệ giữa AI, ML, DL và GenAI
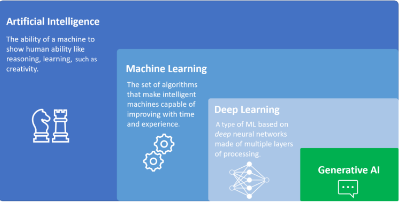
Các mô hình GenAI có thể được huấn luyện dựa trên lượng dữ liệu cực lớn và sau đó chúng có thể tạo ra các ví dụ mới từ đầu bằng cách sử dụng các mẫu trong dữ liệu đó. Quá trình tạo sinh này khác hẳn với các mô hình phân biệt, được huấn luyện để dự đoán lớp hoặc nhãn của một ví dụ cụ thể. Một trong những ứng dụng lớn nhất của GenAI là khả năng tạo nội dung mới bằng ngôn ngữ tự nhiên. Các thuật toán GenAI có thể được sử dụng để tạo văn bản mới, ví dụ một mô hình ngôn ngữ như GPT-3 được phát triển bởi OpenAI có thể huấn luyện trên lượng dữ liệu văn bản lớn và sau đó được sử dụng để tạo ra văn bản mới, mạch lạc và chính xác bằng các ngôn ngữ khác nhau (cả đầu vào lẫn đầu ra).
OpenAI là một tổ chức nghiên cứu được thành lập vào năm 2015 bởi Elon Musk, Sam Altman, Greg Brockman, Ilya Sutskever, Wojciech Zaremba và John Schulman. Như đã nêu trên trang web của OpenAI, sứ mệnh của tổ chức là ‘đảm bảo rằng Trí tuệ Nhân tạo Tổng quát (AGI) mang lại lợi ích cho toàn nhân loại’. AGI được dự định có khả năng học hỏi và thực hiện một loạt các nhiệm vụ mà không cần lập trình cụ thể cho từng nhiệm vụ.
Kể từ năm 2015, OpenAI đã tập trung nghiên cứu vào Học Tăng cường Sâu (DRL), một phân nhánh của học máy (ML) kết hợp Học Tăng cường (RL) với các mạng nơ-ron sâu. Đóng góp đầu tiên trong lĩnh vực này bắt nguồn từ năm 2016 khi công ty phát hành OpenAI Gym, một bộ công cụ cho các nhà nghiên cứu phát triển và kiểm tra các thuật toán RL.
Gym là một API tiêu chuẩn cho học tăng cường và một bộ sưu tập đa dạng các môi trường tham chiếu.
Giao diện Gym đơn giản, mang tính Pythonic và có khả năng đại diện cho các vấn đề RL tổng quát.
OpenAI tiếp tục nghiên cứu và đóng góp trong lĩnh vực này, nhưng những thành tựu đáng chú ý nhất của họ liên quan đến các mô hình tạo sinh – Generative Pre-trained Transformers (GPT).
Vào năm 2020, OpenAI lần đầu tiên công bố và sau đó phát hành GPT-3, với 175 tỷ tham số, đã cải thiện đáng kể kết quả benchmark so với GPT-2.
Ngoài các mô hình tạo sinh ngôn ngữ tự nhiên, OpenAI cũng phát triển trong lĩnh vực tạo hình ảnh, phát hành mô hình đầu tiên trong lĩnh vực này, gọi là DALL-E, được công bố vào năm 2021. Như đã đề cập trong chương trước, DALL-E có khả năng tạo ra hình ảnh hoàn toàn mới từ đầu vào ngôn ngữ tự nhiên, được diễn giải bởi phiên bản mới nhất của GPT-3.
Tổng quan về cách dòng mô hình của OpenAI hiện nay
Không cần là nhà khoa học dữ liệu hay kỹ sư học máy để thao tác với các mô hình này, người dùng có thể tự trải nghiệm các mô hình của OpenAI trong OpenAI Playground
Một số thuật ngữ và thành phần trong OpenAI API:
- Tokens: có thể được coi là các đoạn hoặc phân đoạn từ được API sử dụng để xử lí các lời nhắc đầu vào
- Prompt: trong bối cảnh của xử lí ngôn ngữ tự nheien và ML, prompt đề cập đến một đoạn văn bản được lấy làm đầu vào cho mô hình AI để tạo ra các phản hồi, prompt có thể là một câu hỏi, một tuyên bố, khẳng định và nó sử dụng để cung cấp ngữ cảnh và hướng dẫn cho mô hình AI
- Context: để cập đến các từ và câu xuất hiện trước prompt của người dùng. Context này được dùng để tạo ra từ hoặc cụm từ tiếp theo có khả năng xuất hiện nhất dựa trên các mẫu và mối quan hệ được tìm thấy trong dữ liệu được huấn luyện
- Model confidence: đây là độ tin cậy của một mô hình nó đề cập đến mức độ chắc chắn hoặc xác suất mà một mo hình AI gán cho một dự đoán hoặc một đầu ra cụ thể
Trong Playground có hai mô hình chính có thể thử nghiệm:
- GPT-3: Một tập hợp các mô hình có thể hiểu và tạo ra ngôn ngữ tự nhiên, GPT-3 đã được huấn luyện trên một tập hợp văn bản lớn và có thể thực hiện nhiều nhiệm vụ ngôn ngữ tự nhiên như dịch, tóm tắt, trả lời câu hỏi…
- GPT-3.5: Đây là một tập hợp các mô hình mới hơn được xây dựng dựa trên GPT-3 và nhằm cải thiện khả năng hiểu và tạo ngôn ngữ tự nhiên của nó. Các mô hình GPT-3.5 có thể thực hiện các nhiệm vụ ngôn ngữ tự nhiên phức tạp như soạn thảo các đoạn văn hoặc bài luận mạch lạc, tạo thơ, và thậm chí tạo ra các chương trình máy tính bằng ngôn ngữ tự nhiên. GPT-3.5 là mô hình đứng sau Chat GPT và, ngoài API của nó, nó cũng có thể được sử dụng trong Playground với một giao diện người dùng chuyên dụng
- Codex: Một tập hợp các mô hình có thể hiểu và tạo mã trong nhiều ngôn ngữ lập trình khác nhau. Codex có thể dịch các lời nhắc bằng ngôn ngữ tự nhiên thành mã hoạt động, làm cho nó trở thành một công cụ mạnh mẽ cho phát triển phần mềm
Chat GPT được xây dựng dựa trên một mô hình ngôn ngữ tiên tiến sử dụng phiên bản sửa đổi của GPT-3, đã được tinh chỉnh đặc biệt cho đối thoại. Quá trình tối ưu hóa bao gồm Học Tăng cường với Reinforcement Learning with Human Feedback (RLHF), một kỹ thuật sử dụng đầu vào của con người để huấn luyện mô hình thể hiện các hành vi đối thoại mong muốn.
Chúng ta có thể định nghĩa RLHF là một phương pháp học máy mà thuật toán học cách thực hiện một nhiệm vụ bằng cách nhận phản hồi từ con người. Thuật toán được huấn luyện để đưa ra các quyết định tối đa hóa tín hiệu thưởng do con người cung cấp, và con người cung cấp phản hồi bổ sung để cải thiện hiệu suất của thuật toán. Phương pháp này hữu ích khi nhiệm vụ quá phức tạp đối với lập trình truyền thống hoặc khi kết quả mong muốn khó xác định trước.
Điểm khác biệt quan trọng ở đây là Chat GPT đã được huấn luyện với sự tham gia của con người để nó phù hợp với người dùng. Bằng cách tích hợp RLHF, Chat GPT được thiết kế để hiểu và phản hồi ngôn ngữ của con người một cách tự nhiên và hấp dẫn hơn.
Kĩ thuật Prompt (Prompt Engineer)
- Prompt: là đầu vào hoặc truy vấn mà ta cung cấp cho mô hình ngôn ngữ (LLM) để thu được một phản hồi cụ thể
- Prompt engineer: là kỹ thuật giao tiếp với LLM để điều khiển hành vi của nó để đạt được kết quả mong muốn mà không cần phải cập nhật trọng số cho mô hình
Để đạt được hiệu quả giao tiếp và tối ưu hiệu quả từ mô hình, cần có một phương pháp viết hiệu quả, cụ thể cần đáp ứng những yêu cầu sau:
- Rõ ràng và cụ thể: prompt cần rõ ràng và cụ thể giúp mô hình hiểu chính xác, tránh những câu hỏi mơ hồ. Ví dụ, thay vì hỏi “Hãy giải thích cho tôi về điều này được không?”, hãy hỏi “Bạn có thể giải thích chi tiết về cách hoạt động của blockchain không?”.
- Cung cấp ngữ cảnh: đưa ngữ cảnh hoặc thông tin nền để mô hình hiểu hơn về yêu cầu, giúp nó đưa ra phản hồi chính xác hơn. Ví dụ, khi đưa yêu cầu mô hình viết một đoạn văn bản, bạn có thể cung cấp ngữ cảnh về đối tượng độc giả và mục đích của đoạn văn.
- Sử dụng ví dụ: đưa một ví dụ cụ thể minh họa cho yêu cầu. Ví dụ, bạn cần viết một đoạn giới thiệu, bạn có thể cung cấp một đoạn giới thiệu mẫu để mô hình dựa vào.
- Thử nghiệm và điều chỉnh: nếu phản hồi không như mong đợi, hẫy điều chỉnh prompt để cải thiện kết quả. Ví dụ,
- Prompt 1: “Hãy mô tả một con mèo”. Kết quả: “Một con mèo là một động vật có lông, thường nhỏ và mềm mại, với bốn chân và một cái đuôi dài. Chúng có nhiều màu sắc khác nhau và thường được nuôi làm thú cưng.”
- Prompt 2: “Hãy mô tả chi tiết hơn về hính dáng và hành vi của một con mèo”. Kết quả: “Mèo có thân hình mảnh mai và uyển chuyển, với bộ lông mềm mại và thường bóng mượt. Đôi mắt của chúng có thể phản chiếu ánh sáng vào ban đêm, giúp chúng nhìn rõ trong bóng tối. Mèo thường di chuyển nhẹ nhàng, yên lặng và có tính cách độc lập nhưng cũng có lúc rất tình cảm và gần gũi với con người.”
Bằng cách sử dụng những phương pháp này, prompts có thể được tối ưu hóa để đạt được kết quả mong muốn từ mô hình ngôn ngữ lớn một cách hiệu quả.