

Trí tuệ nhân tạo (AI) đang trở thành một trong những công nghệ tiên tiến và được nhắc đến nhiều nhất trong thời gian gần đây. AI không chỉ đóng vai trò quan trọng trong các lĩnh vực công nghệ mà còn ảnh hưởng sâu rộng đến các ngành công nghiệp khác nhau như y tế, tài chính, sản xuất, giao thông vận tải và nghệ thuật. AI được ứng dụng trong việc thực hiện các chẩn đoán y tế, tổng hợp các hóa chất mới, xác định khuôn mặt của tội phạm trong đám đông, điều khiển ô tô tự lái và thậm chí tạo ra các tác phẩm nghệ thuật mới.
Sự phát triển nhanh chóng của AI đã dẫn đến sự xuất hiện của các công nghệ chuyên biệt hơn, được gọi là Học máy (Machine Learning), dựa vào khả năng học tập từ dữ liệu để đưa ra các quyết định và dự đoán. Học máy đã đặt nền móng cho những gì đã trở thành Học sâu (Deep Learning), bao gồm các thuật toán phân lớp nhằm đạt được sự hiểu biết sâu sắc hơn về dữ liệu thông qua các mạng nơ-ron phức tạp. Để đáp ứng nhu cầu tính toán khổng lồ của các ứng dụng AI, các nhà sản xuất phần cứng đã phát triển những chip chuyên dụng, được gọi là Chip AI. Những chip này được thiết kế đặc biệt để tối ưu hóa hiệu năng cho các tác vụ học máy và học sâu, vượt trội hơn so với các chip truyền thống như CPU và GPU trong việc xử lý các mô hình AI phức tạp. Báo cáo này sẽ so sánh Chip AI với các Chip Thường, phân tích kiến trúc cụ thể của các Chip AI, và thảo luận về các ứng dụng thực tế cũng như triển vọng phát triển trong tương lai
1. Kiến trúc chip AI khác gì so với các kiến trúc chip thông thường
Để thực hiện các tác vụ học máy và tính toán ma trận hiệu quả, các chip AI thường sử dụng các đơn vị chuyên dụng (Processing Unit), ví dụ như NPU (Neural Processing Unit) và TPU (Tensor Processing Unit). Những đơn vị này được thiết kế đặc biệt để tối ưu hóa hiệu suất và tiết kiệm năng lượng trong các tác vụ tính toán sâu, nơi mà khối lượng dữ liệu lớn và độ phức tạp cao là điều phổ biến.
NPU là một loại vi xử lý được tối ưu hóa cho việc thực hiện các thuật toán học sâu, cho phép xử lý nhanh chóng và hiệu quả các mạng nơ-ron. Trong khi đó, TPU, phát triển bởi Google, là một giải pháp phần cứng mạnh mẽ, được thiết kế để xử lý các phép toán tensor – một thành phần quan trọng trong học sâu. Cả hai loại chip này không chỉ giúp cải thiện tốc độ tính toán mà còn làm giảm đáng kể mức tiêu thụ điện năng, mang lại hiệu quả vượt trội so với các bộ vi xử lý truyền thống.
2. Một vài Processing Unit thường được sử dụng
2.1 NPU (Neural Processing Unit)
Một NPU core là một đơn vị xử lý bên trong một SoC. Đơn vị này là một phần thiết yếu của việc tính toán, xử lí những tác vụ của AI.
Nếu chip có các lõi NPU tốt, chip đó có thể thực hiện các nhiệm vụ AI sau:
- Nhận diện khuôn mặt,
- Phát hiện đối tượng trong ảnh,
- Nhận diện giọng nói trong các trợ lý ảo,
- Nhận diện và dịch từ,
- Nhận diện và dịch ngôn ngữ.
Cách hoạt động của NPU
Một NPU điển hình được phát triển với kiến trúc “tính toán song song dựa trên dữ liệu”. Kiến trúc này đặc biệt tốt cho việc xử lý nhiều dữ liệu đa phương tiện như video, hình ảnh và âm thanh. Tính toán song song dựa trên dữ liệu là cách sử dụng nhiều máy tính hoặc các phần của máy tính để làm việc trên một vấn đề cùng một lúc. Nó hữu ích cho việc giải quyết các vấn đề liên quan đến nhiều dữ liệu, chẳng hạn như phân tích tập dữ liệu lớn, mô phỏng các hệ thống phức tạp hoặc tạo ra đồ họa thực tế. Tính toán song song dựa trên dữ liệu có thể làm cho việc tính toán nhanh hơn, hiệu quả hơn và chính xác hơn so với việc sử dụng một máy tính đơn lẻ.
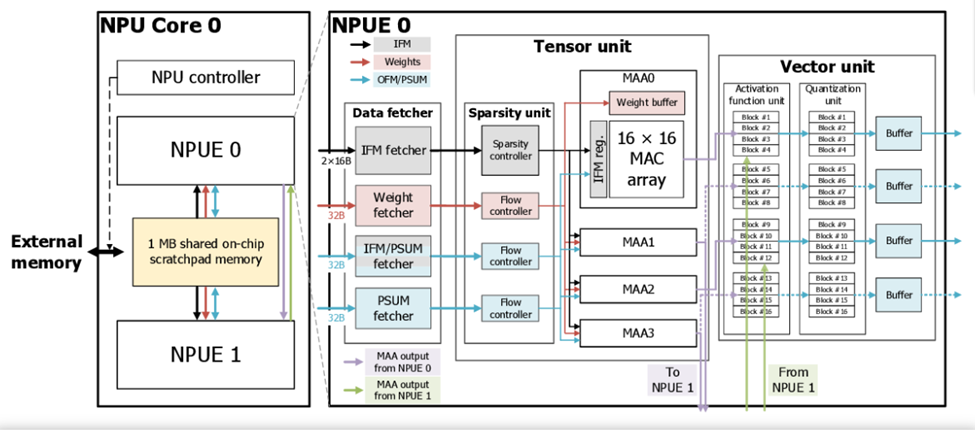
Kiến trúc NPU của samsung
NPU của Samsung bao gồm các thành phần quan trọng như 16×16 MAC array, sparsity unit, và MMA (Matrix Multiply Accumulate), giúp tối ưu hóa hiệu suất tính toán cho các tác vụ AI. Mảng 16×16 MAC cho phép thực hiện đồng thời 256 phép toán nhân và cộng, đáp ứng nhu cầu tính toán phức tạp trong các mô hình học sâu trong điện thoại. Sparsity unit tận dụng các mô hình mạng nơ-ron thưa bằng cách loại bỏ các trọng số không quan trọng, giảm bớt khối lượng dữ liệu cần xử lý và tiết kiệm tài nguyên tính toán. Cuối cùng, MMA cho phép thực hiện phép nhân và cộng ma trận đồng thời, tăng tốc độ xử lý và hiệu suất của các tác vụ AI. Sự kết hợp của những thành phần này không chỉ nâng cao hiệu suất tính toán mà còn tiết kiệm năng lượng, cải thiện trải nghiệm người dùng trên các thiết bị di động.
2.2 TPU (Tensor Processing Unit) của Google
Tính linh hoạt là một mục tiêu thiết kế quan trọng đối với TPU. TPU không chỉ được thiết kế để chạy một loại mô hình mạng nơ-ron duy nhất. Thay vào đó, nó được thiết kế để đủ linh hoạt nhằm tăng tốc các phép toán cần thiết để chạy nhiều loại mô hình mạng nơ-ron khác nhau.
Hầu hết các CPU hiện đại đều được thiết kế theo kiến trúc tập lệnh Reduced Instruction Set Computer (RISC). Với RISC, trọng tâm là xác định các lệnh đơn giản (ví dụ: load, store, cộng và nhân) mà thường được sử dụng bởi hầu hết các ứng dụng và sau đó thực hiện các lệnh đó nhanh nhất có thể. Thay vào đó,Google đã chọn kiểu thiết kế Complex Instruction Set Computer (CISC) làm cơ sở cho tập lệnh TPU. Thiết kế CISC tập trung vào việc triển khai các lệnh cấp cao có thể thực hiện các tác vụ phức tạp hơn (như tính toán nhân và cộng nhiều lần) với mỗi lệnh.
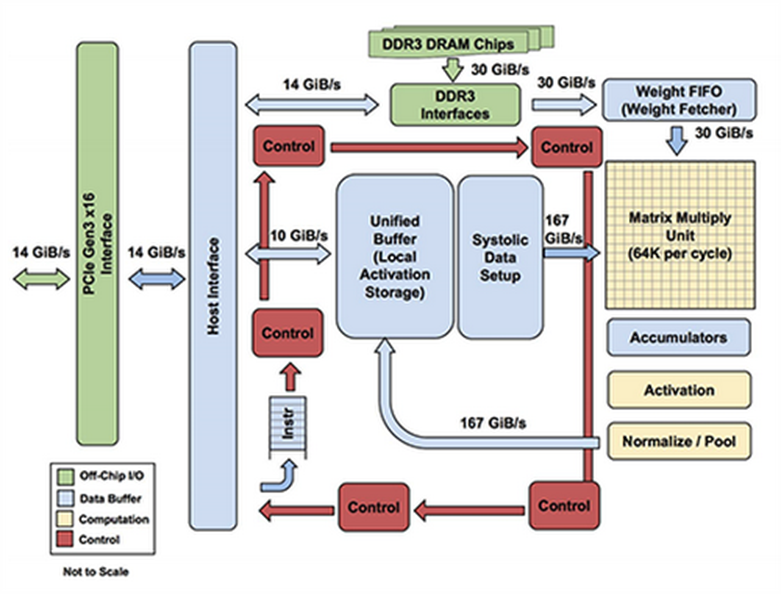
Kiến trúc TPU
Các thành phần trong TPU được sử dụng để tính toán:
- Matrix Multiplier Unit (MXU): 65,536 đơn vị nhân và cộng 8-bit cho các phép toán ma trận.
- Unified Buffer (UB): 24MB SRAM hoạt động như các thanh ghi.
- Activation Unit (AU): Các hàm kích hoạt được lập trình cứng.
Để điều khiển cách hoạt động mà MXU, UB và AU tiến hành thực hiện các phép toán, Google đã định nghĩa rất nhiều lệnh cấp cao đặc biệt được thiết kế cho việc suy diễn mạng nơ-ron. Dưới đây là năm phép toán nổi bật trong số đó
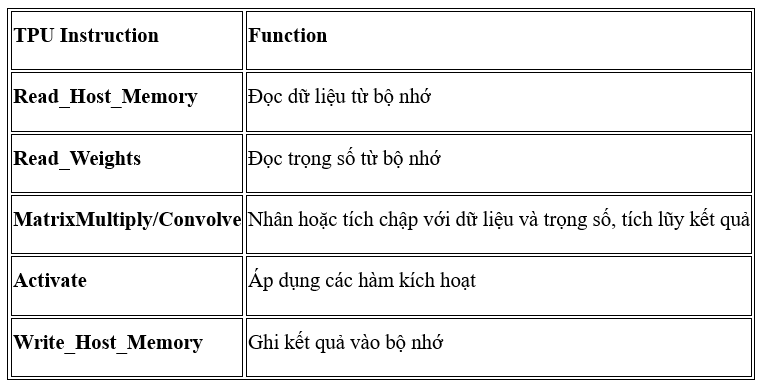
Tập lệnh này tập trung vào các phép toán toán học chính cần thiết cho suy diễn mạng nơ-ron: thực hiện phép nhân ma trận giữa dữ liệu đầu vào và trọng số.
TPU đã trở thành một phần quan trọng trong việc cải thiện hiệu suất của các ứng dụng AI, giúp giảm thời gian huấn luyện và suy diễn mô hình mạng nơ-ron.
Tóm lại, thiết kế TPU gói gọn bản chất của phép toán mạng nơ-ron và có thể được lập trình cho nhiều loại mô hình mạng nơ-ron khác nhau. Để lập trình TPU, Google đã tạo ra một trình biên dịch và một stack để chuyển đổi các lệnh API từ đồ thị TensorFlow thành các lệnh TPU.
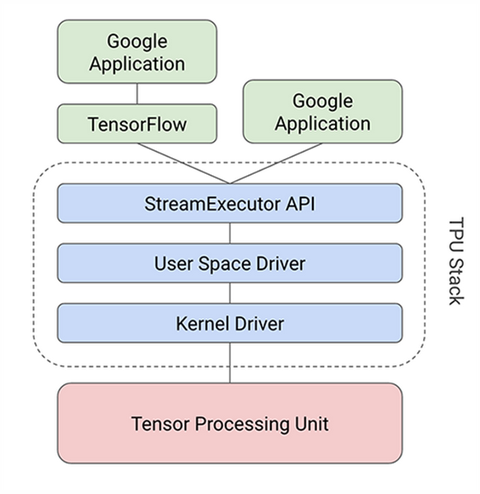
Luồng thực thi của ứng dụng khi sử dụng TPU
3. Tổng kết
Trong bối cảnh công nghệ phát triển nhanh chóng, chip AI đang đóng vai trò ngày càng quan trọng trong việc nâng cao hiệu suất và khả năng xử lý của các ứng dụng trí tuệ nhân tạo. Các loại chip như NPU và TPU đã được thiết kế đặc biệt để tối ưu hóa cho các tác vụ học máy và học sâu, mang lại hiệu quả vượt trội so với các chip truyền thống như CPU và GPU.
NPU của Samsung với kiến trúc tính toán song song và các thành phần như mảng 16×16 MAC, sparsity unit, và MMA đã cho thấy khả năng xử lý vượt trội trong các tác vụ nhận diện khuôn mặt, phát hiện đối tượng, và xử lý âm thanh. Trong khi đó, TPU của Google không chỉ linh hoạt trong việc xử lý nhiều loại mô hình mạng nơ-ron khác nhau mà còn tối ưu hóa các phép toán cần thiết cho suy diễn mạng nơ-ron thông qua thiết kế kiến trúc CISC và các lệnh cấp cao chuyên biệt.
Sự kết hợp giữa hiệu suất cao và tiết kiệm năng lượng của các chip AI không chỉ nâng cao khả năng thực hiện các tác vụ phức tạp mà còn mở ra nhiều cơ hội ứng dụng mới trong các lĩnh vực như y tế, tài chính, và giao thông vận tải. Với sự phát triển không ngừng của công nghệ AI, chip AI hứa hẹn sẽ tiếp tục cải thiện và đổi mới, trở thành nền tảng cho những ứng dụng thông minh trong tương lai.
Link tham khảo:
https://cloud.google.com/blog/products/ai-machine-learning/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu
https://semiconductor.samsung.com/us/support/tools-resources/dictionary/the-neural-processing-unit-npu-a-brainy-next-generation-semiconductor/