
Cached memory được hiểu là vùng nhớ đệm nằm sát với core, CPU thông thường sẽ không truy cập trực tiếp vào RAM mà sẽ nạp ram vào cached và sử dụng dữ liệu ở trong cached
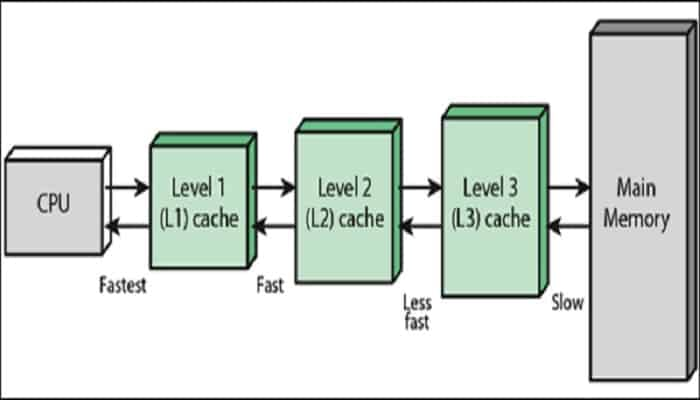
Định kỳ hoặc gặp một điều kiện nào đó, CPU sẽ tiến hành đồng bộ 2 vùng nhớ này với nhau. Quá trình này diễn ra một cách trong suốt đối với người lập trình viên.
Có khi nào các bạn nghĩ mình sẽ phải xử lý lỗi liên quan đến cached memory ở trong dự án của mình?
Chương trình của mình có 2 thread, 1 thread lấy dữ liệu từ sensor bên ngoài và đẩy vào queue
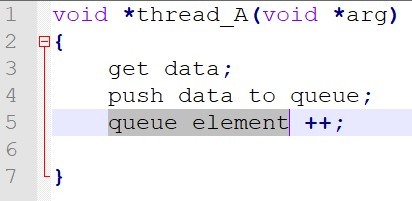
1 thread khác lấy dữ liệu từ queue và xử lý
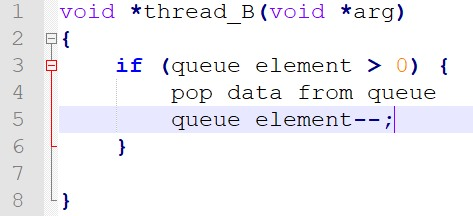
Tuy nhiên có 1 vấn đề xảy ra. Thỉnh thoảng thread B không nhận được dữ liệu, hoặc dữ liệu đọc từ queue của thread B là dữ liệu rác, mặc dù dưới sensor vẫn đẩy dữ lên bình thường.
Nếu như mình đặt log ở thread B để in ra dữ liệu mà nó nhận được từ queue thì bug sẽ tự nhiên biến mất. Nếu không có hiểu biết về cơ chế hoạt động của bộ nhớ cached thì việc xử lý lỗi này sẽ rất mất thời gian.
Do cơ chế lập lịch nên thread A và B sẽ được phân tán sang các core khác nhau (core 1 và 2) để tối ưu tài nguyên của hệ thống

Và do cơ chế cached, vùng nhớ dữ liệu nằm trong queue cũng có 3 bản thể, trong đó bản chính nằm trên ram, 2 bản thể phụ nằm trên cached của core 1 và 2. Mỗi core sẽ thao tác với dữ liệu trên bản thể của mình và việc đồng bộ giữa các bản thể phụ với bản chính sẽ do hệ điều hành quyết định.
Đến đây thì chúng ta đã biết lỗi này là do sự mất đồng bộ giữa các bản thể của dữ liệu trong hệ thống. Nếu chúng ta xác định data theo kiểu volatile thì liệu lỗi này có được xử lý? Ví dụ khai báo data như sau: char volatile data[1024].
Việc khai báo dữ liệu (data) là vùng nhớ volatile sẽ khiến cho CPU phải truy cập thẳng vào RAM, từ đó trong hệ thống chỉ còn 1 bản thể duy nhất của Data. Tuy nhiên lỗi vẫn không được xử lý. Nguyên nhân là do mỗi khi thay đổi dữ liệu của 1 word nhớ của data, cpu vẫn phải nạp word đó vào thanh ghi của mình. Lấy ví dụ như câu lệnh data[1]– sẽ được dịch ra 3 câu lệnh assembly như hình 5. Do 2 thread chạy ở 2 core, nên sẽ có xác suất cả 2 core đều chạy đồng thời đoạn mã assembly lên, kết quả là giá trị của data[1] ở trên ram chỉ được tăng lên 1 thay vì tăng lên 2.
Để xử lý được vấn đề này, chúng ta bắt buộc phải dùng mutex. Giống như hình dưới:

Việc sử dụng mutex sẽ khiến cho 2 core không thể chạy đồng thời được đoạn mã assembly nhằm thay đổi giá trị của biến a[1]

Mình thử áp dụng và thấy lỗi đã được xử lý.
Tuy nhiên không khó để có thể nhận ra 1 điểm không hợp lý ở đây. Việc sử dụng mutex chỉ khiến cho các core không thể đồng thời thay đổi giá trị của 1 biến nằm trong ram. Tuy nhiên, không hề đảm bảo việc dữ liệu không bị cached trên các core. Vậy tại sao mutex lại sửa được lỗi này? Vì nếu vẫn bị cached thì lỗi này chắc chắn sẽ chưa xử lý được?
Câu trả lời chính là thuộc tính thứ 2 của mutex – memory barier. Tất cả các đoạn code đằng sau hàm mutex lock đều có thuộc tính volatile, nên core sẽ truy cập thẳng vào ram và bỏ qua cached.
(Các bạn có thể tham khảo tính chất thứ hai của mutex tại: https://stackoverflow.com/…/how-does-a-mutex-ensure-a… )